The full code for this project is available in this kaggle notebook.
I’ve been self-studying machine learning recently, and I’m having a lot of fun. It’s been a long time since I’ve had the opportunity to systematically digest the basics of a new field. High quality resources for this material are abundant (e.g. Andrej Karpathy’s videos), and in a meta twist the chatbots themselves are incredibly useful for learning the technology behind chatbots. This has of course been great for my learning rate, but spoon-feeding eventually makes me a bit restless. I was excited, then, to finally engage with a question that chatbots and google-foo couldn’t answer. My experiments for it are the subject of this blog post.
For the past couple of weeks I’ve been studying reinforcement learning (RL) by going through OpenAI Spinning Up and playing around with implementations of some standard RL algorithms for the CartPole-v1 environment in the gymnasium package. This environment simulates a pole with one end attached to a cart. You control the cart, and your goal is to keep the pole balanced above the cart. A visualization of a well-trained model can be found here.
The state space consists of your position, velocity, angle, and angular velocity, represented as floats. The action space just consists of 0 and 1, corresponding to left and right. The reward is the number of time steps elapsed. The episode is either terminated when the angle exceeds 24 degrees, or truncated once the reward reaches 500.
The algorithms I’ve played with so far are tabular Q-learning (with a discretized version of the environment), deep Q-network (DQN), vanilla policy gradient (VPG), and finally Proximal Policy Optimization (PPO). There was a clear hierarchy of performance, with PPO alone at the top. It dominated in both sample efficiency and wall-clock time. Admittedly I didn’t try very hard to optimize the other models’ hyperparameters, but part of the advantage of PPO is that you don’t need to work as hard to get good performance.
Here are some typical runs from each algorithm:
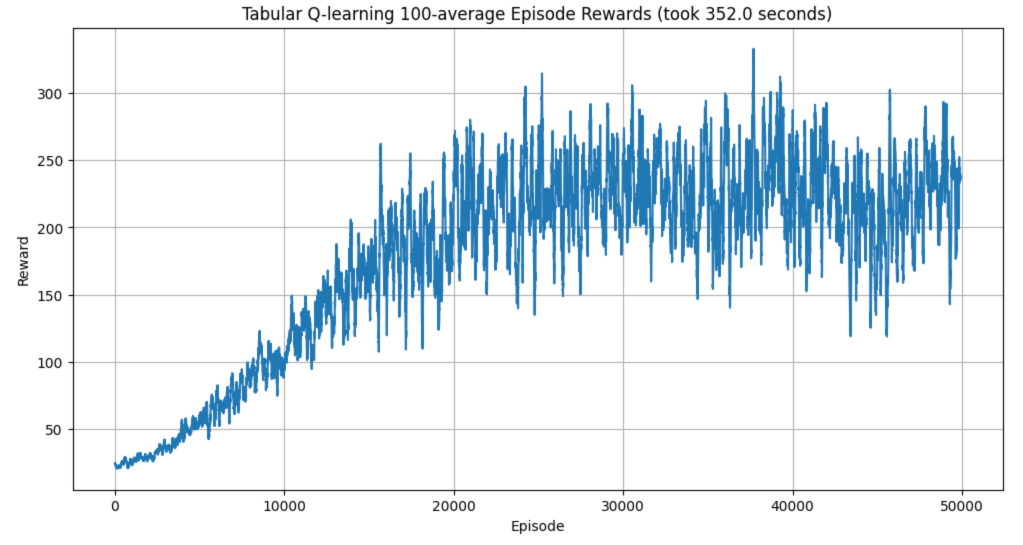
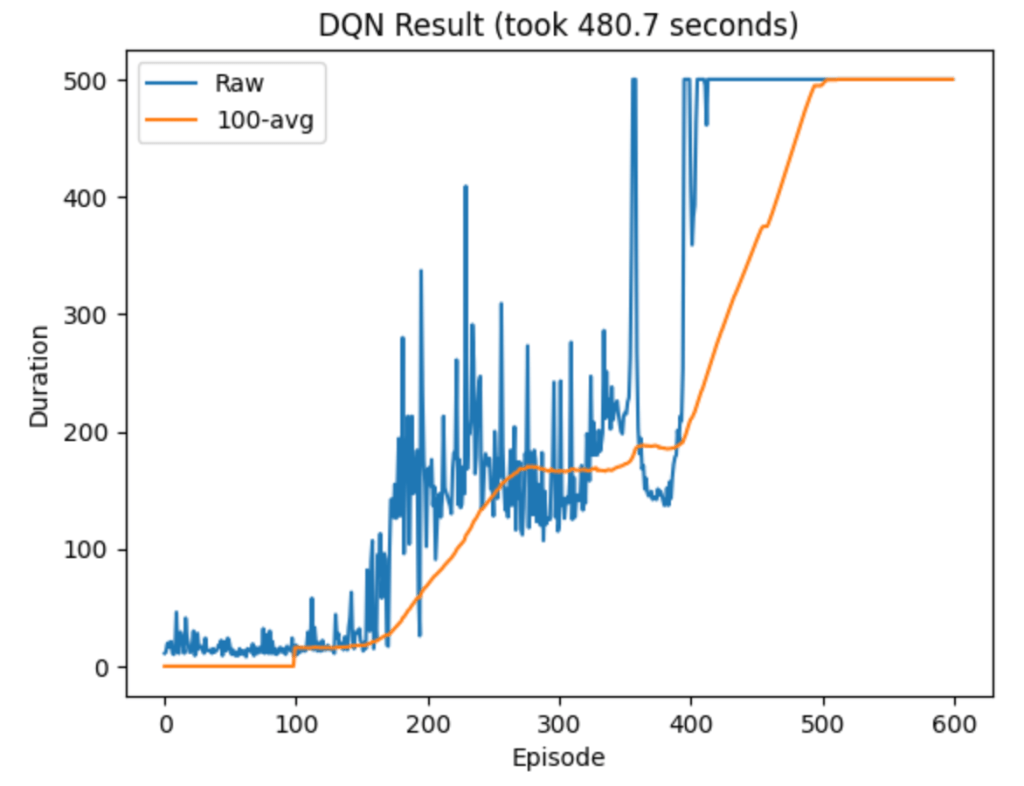
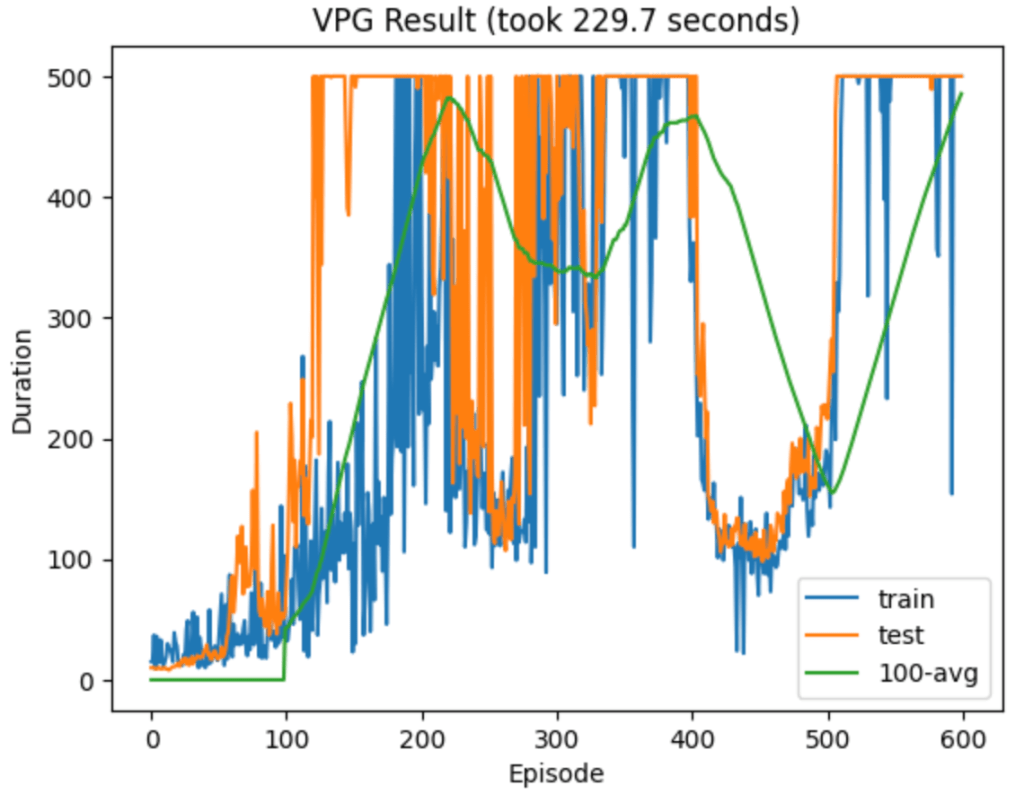
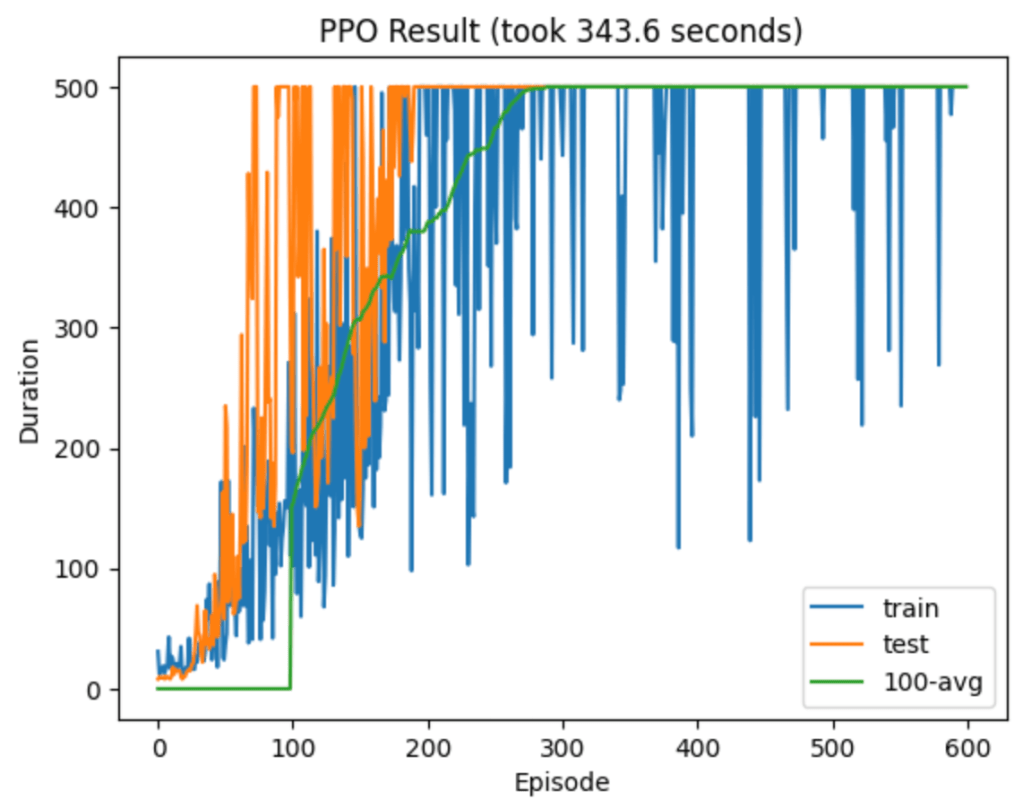
The dominance of PPO got me wondering which aspects contribute most to its success. The main differences from VPG are that it takes multiple optimization steps after each episode, it uses a different surrogate loss, and it clips this loss if the new policy strays too far from the previous one. (I’ll use “loss” and “objective” interchangeably, even though the latter is more technically correct here.)
Writing ![J[\pi_\theta] = E_{\pi_\theta}[R[\tau]]](https://s0.wp.com/latex.php?latex=J%5B%5Cpi_%5Ctheta%5D+%3D+E_%7B%5Cpi_%5Ctheta%7D%5BR%5B%5Ctau%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)


![\nabla_\theta J[\pi_\theta] = E_{\pi_\theta}\big[ R[\tau] \nabla_\theta \log \pi_\theta[\tau] \big]](https://s0.wp.com/latex.php?latex=%5Cnabla_%5Ctheta+J%5B%5Cpi_%5Ctheta%5D+%3D+E_%7B%5Cpi_%5Ctheta%7D%5Cbig%5B+R%5B%5Ctau%5D+%5Cnabla_%5Ctheta+%5Clog+%5Cpi_%5Ctheta%5B%5Ctau%5D+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
where ![\nabla_\theta \log \pi_\theta[\tau]](https://s0.wp.com/latex.php?latex=%5Cnabla_%5Ctheta+%5Clog+%5Cpi_%5Ctheta%5B%5Ctau%5D&bg=ffffff&fg=000&s=0&c=20201002)
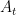
![R[\tau]](https://s0.wp.com/latex.php?latex=R%5B%5Ctau%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\nabla_\theta J[\pi_\theta] = \sum_t E_{\pi_\theta}\big[ A_t \nabla_\theta \log \pi_{\theta, t} \big]](https://s0.wp.com/latex.php?latex=%5Cnabla_%5Ctheta+J%5B%5Cpi_%5Ctheta%5D+%3D+%5Csum_t+E_%7B%5Cpi_%5Ctheta%7D%5Cbig%5B+A_t+%5Cnabla_%5Ctheta+%5Clog+%5Cpi_%7B%5Ctheta%2C+t%7D+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
where I’m using 

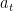

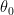

![L^{PG}(\theta; \theta_0) \equiv \sum_t E_{\pi_{\theta_0}} \big[ A_t \log \pi_{\theta, t} \big]](https://s0.wp.com/latex.php?latex=L%5E%7BPG%7D%28%5Ctheta%3B+%5Ctheta_0%29+%5Cequiv+%5Csum_t+E_%7B%5Cpi_%7B%5Ctheta_0%7D%7D+%5Cbig%5B+A_t+%5Clog+%5Cpi_%7B%5Ctheta%2C+t%7D+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
The policy gradient coincides with the gradient of 

![(\nabla_\theta L^{PG})|_{\theta = \theta_0} = \nabla_\theta J[\pi_\theta]](https://s0.wp.com/latex.php?latex=%28%5Cnabla_%5Ctheta+L%5E%7BPG%7D%29%7C_%7B%5Ctheta+%3D+%5Ctheta_0%7D+%3D+%5Cnabla_%5Ctheta+J%5B%5Cpi_%5Ctheta%5D&bg=ffffff&fg=000&s=0&c=20201002)
Introductory policy gradient discussions emphasize repeatedly that this should not be misinterpreted as saying that ![J[\pi_\theta]](https://s0.wp.com/latex.php?latex=J%5B%5Cpi_%5Ctheta%5D&bg=ffffff&fg=000&s=0&c=20201002)

With this warning fresh in my mind, it seemed strange that PPO continues to use a surrogate loss even after
![L^{PPO}(\theta; \theta_0) \equiv \sum_t E_{\pi_{\theta_0}} \big[ \frac{\pi_{\theta,t}}{\pi_{\theta_0, t}} A_t \big]](https://s0.wp.com/latex.php?latex=L%5E%7BPPO%7D%28%5Ctheta%3B+%5Ctheta_0%29+%5Cequiv+%5Csum_t+E_%7B%5Cpi_%7B%5Ctheta_0%7D%7D+%5Cbig%5B+%5Cfrac%7B%5Cpi_%7B%5Ctheta%2Ct%7D%7D%7B%5Cpi_%7B%5Ctheta_0%2C+t%7D%7D+A_t+%5Cbig%5D&bg=ffffff&fg=000&s=0&c=20201002)
where 
First Hypothesis
To test this hypothesis, I modified the PPO algorithm to use 
def calculate_surrogate_loss(
actions_log_probability_old,
actions_log_probability_new,
epsilon,
advantages):
advantages = advantages.detach()
policy_ratio = (
actions_log_probability_new - actions_log_probability_old
).exp()
surrogate_loss_1 = policy_ratio * advantages
surrogate_loss_2 = torch.clamp(
policy_ratio, min=1.0-epsilon, max=1.0+epsilon
) * advantages
surrogate_loss = torch.min(surrogate_loss_1, surrogate_loss_2)
return surrogate_loss
The inputs here are the clipping parameter 




def calculate_surrogate_loss(
actions_log_probability_old,
actions_log_probability_new,
epsilon,
advantages):
advantages = advantages.detach()
surrogate_loss_1 = actions_log_probability_new * advantages
clamped_log_probs = torch.clamp(actions_log_probability_new,
actions_log_probability_old + np.log(1-epsilon),
actions_log_probability_old + np.log(1+epsilon)
)
surrogate_loss_2 = clamped_log_probs * advantages
surrogate_loss = torch.min(surrogate_loss_1, surrogate_loss_2)
return surrogate_loss
This is very similar, but it uses 


I found my modified PPO algorithm’s test performance to be comparably excellent to the original version, although for some reason its training performance seemed noisier. Here is a typical run from the modified version:
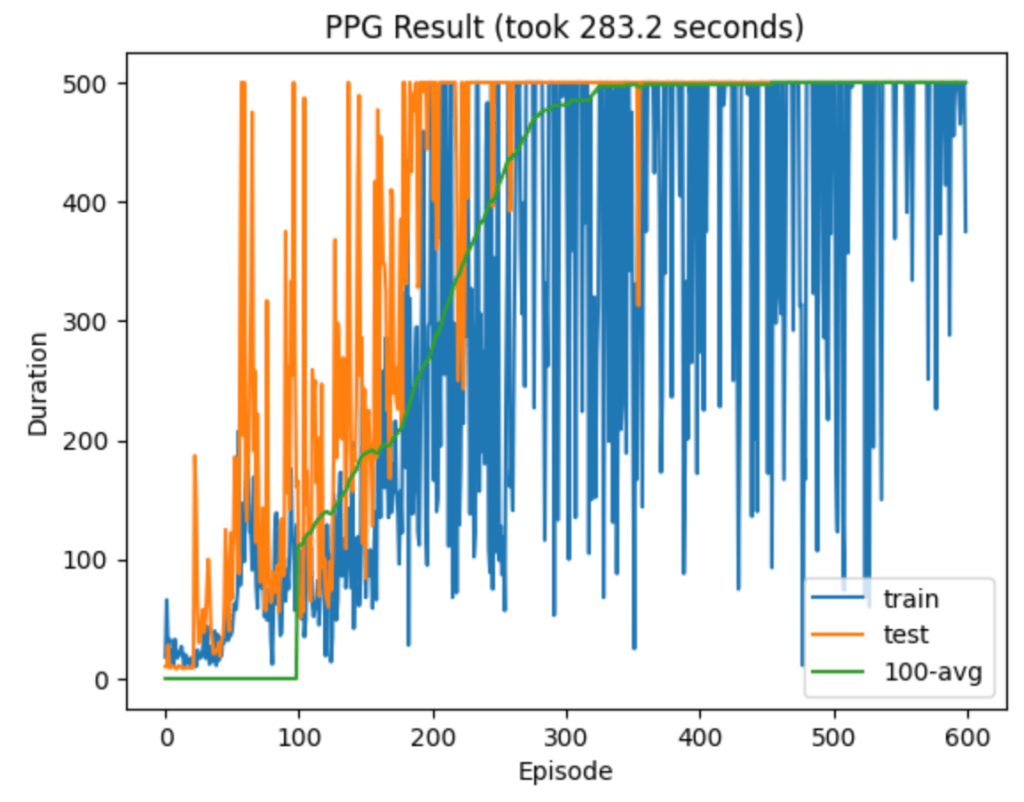
After a bit more searching around online, I actually did find a paper by Gyun et al. answering this exact question. They too modified PPO to use
This is not too surprising considering that the two losses are related (up to a constant shift) by simply replacing the policy ratio with its log, and 
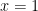

Second Hypothesis
This was a nice confirmation of my first hypothesis, but a mystery still remained. How was it possible that PPO and its modification PPG performed so well despite “misusing” their surrogate losses by continuing to use them after 

I found this truncation a bit tricky to implement. Initially I hoped that I could just compute the loss once per episode, at the start of the optimization loop when
I got around this by maintaining an auxiliary copy of the policy net, whose parameters I’ll denote by 



In terms of actual code, the changes were to the surrogate loss function and the optimization loop. My new surrogate loss function reads
def calculate_surrogate_loss(
actions_log_probability_old,
actions_log_probability_new,
actions_log_probability_aux,
epsilon,
advantages):
advantages = advantages.detach()
policy_ratio_new = (
actions_log_probability_new - actions_log_probability_old
).exp()
policy_ratio_aux = (
actions_log_probability_aux - actions_log_probability_old
).exp()
# Implement clipping with mask instead of min
# Technically this objective differs by a constant, but it has the same grad
# Mask is true where the loss is NOT clipped
mask = ((advantages < 0) & (1-epsilon < policy_ratio_aux)) | ((advantages > 0) & (policy_ratio_aux < 1+epsilon))
surrogate_loss = (policy_ratio_new * advantages).masked_fill(~mask, 0)
return surrogate_loss
I added the argument actions_log_probability_aux (corresponding to
for _ in range(ppo_steps):
# Get new log prob of actions for all input states
action_pred, value_pred = agent(states)
value_pred = value_pred.squeeze(-1)
action_prob = f.softmax(action_pred, dim=-1)
probability_distribution_new = distributions.Categorical(action_prob)
entropy = probability_distribution_new.entropy()
# Estimate new log probabilities using old actions
actions_log_probability_new = probability_distribution_new.log_prob(actions)
# I added this code for the auxiliary net
# Get aux log prob of actions for all input states
action_pred_aux, value_pred_aux = agent_aux(states)
value_pred_aux = value_pred_aux.squeeze(-1)
action_prob_aux = f.softmax(action_pred_aux, dim=-1)
probability_distribution_aux = distributions.Categorical(action_prob_aux)
entropy_aux = probability_distribution_aux.entropy()
# Estimate aux log probabilities using old actions
actions_log_probability_aux = probability_distribution_aux.log_prob(actions)
actions_log_probability_aux = actions_log_probability_aux.detach()
# Use my new version of surrogate loss
surrogate_loss = calculate_surrogate_loss(
actions_log_probability_old,
actions_log_probability_new,
actions_log_probability_aux,
epsilon,
advantages)
policy_loss, value_loss = calculate_losses(
surrogate_loss,
entropy,
entropy_coefficient,
returns,
value_pred)
# Compute the theta gradient
optimizer.zero_grad()
policy_loss.backward()
value_loss.backward()
# Transfer the theta gradient to theta_aux
opt_aux.zero_grad()
for param_src, param_aux in zip(agent.parameters(), agent_aux.parameters()):
if param_src.grad is not None:
param_aux.grad = param_src.grad.clone()
# Update theta_aux
opt_aux.step()
# Now that optimization loop is done, update theta to match theta_aux
agent.load_state_dict(agent_aux.state_dict())
Note that I never call optimizer.step(), because I don’t want to update
Below are some plots of the new model’s performance. The latter plot is more typical.
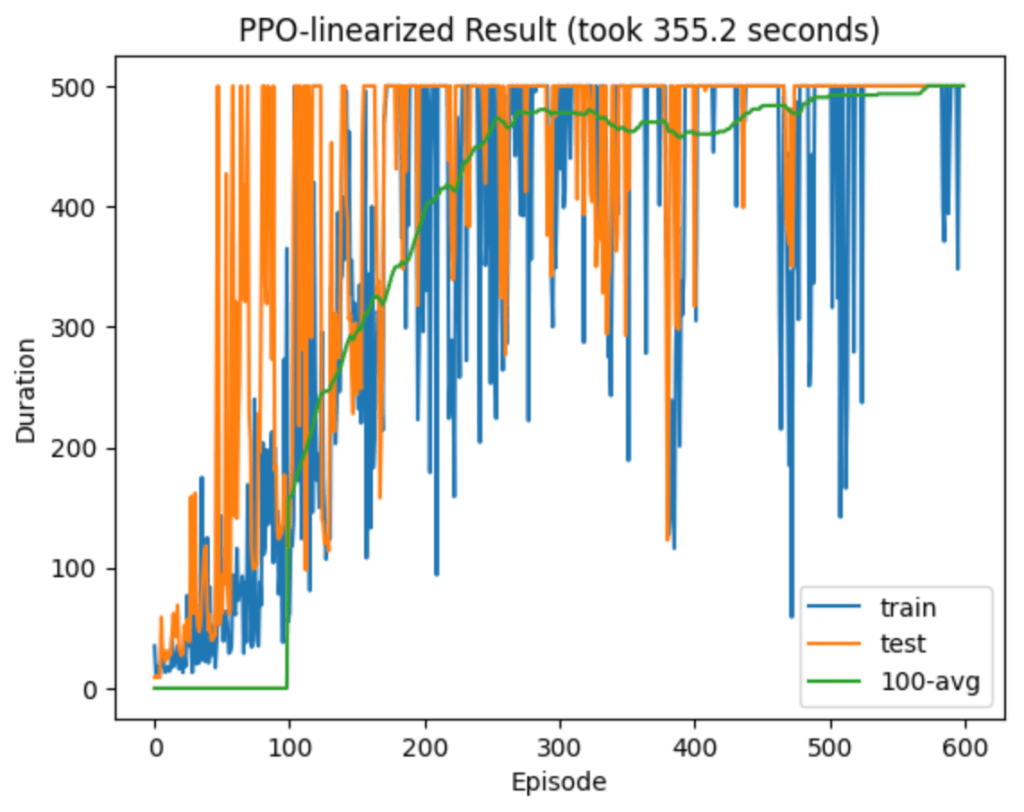
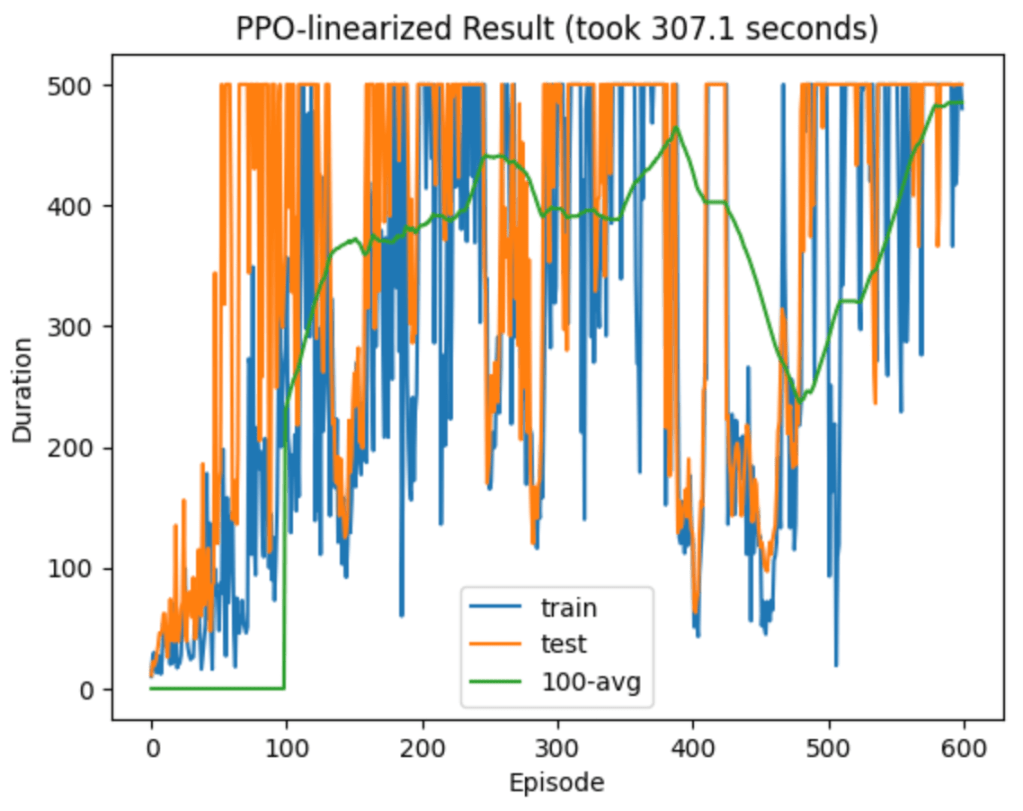
It’s noticeably worse than both PPO and PPG! It still learns quickly, but it seems prone to deep relapses into poor play. The initial learning, for the first 100 or so episodes, is still impressive and comparable to the PPO and PPG algorithms. In this regime my second hypothesis of sensitivity only to the linear part of the loss does seem plausible. But this model’s instability after attaining perfect play at least partially refutes my second hypothesis, and I don’t yet understand why it happens.
To recap, I have tested three versions of PPO using different surrogate losses 

I found that truncating
It would be interesting to explore this further, but at this point I am getting well beyond the 80/20 rule of thumb for optimal use of one’s time. A reasonable next step would be to simultaneously track the gradients of multiple different loss types and see when they differ most, with special focus on relapses. Also, the instability after initially reaching perfect play could plausibly be mitigated by an appropriate learning rate schedule, in contrast with the constant learning rate used throughout my experiments. For now I will set these questions aside, and hopefully return to them later once I am a more experienced machine learning researcher.

Leave a comment